

This article is part of a series created to demystify natural language and help you use it in your own applications.
Part 1 – Natural Language for Simulations (this page)
Part 2 – NLU for XR with LUIS
Part 3 – Custom Intent Handlers (coming soon)
Part 4 – Resolution and Routing (coming soon)
Table of Contents
Intro
Natural Language Understanding (or NLU) is the study of teaching computers to understand humans — the way we communicate naturally. But how does natural language work, and what problems does it solve for XR simulations?
“The most profound technologies are those that disappear. They weave themselves into the fabric of everyday life until they are indistinguishable from it.” -Mark Weiser
Mark Weiser was a Principal Scientist at Xerox PARC and is best known as the ‘godfather of ubiquitous computing’. Many of the technological advances he predicted have become a reality in our daily lives.
XR developers may understand the importance of ubiquitous computing better than any other discipline. Though VR developers strive for immersion and MR developers incorporate the physical world, they both seek to engage the user so naturally that the software itself disappears.
Speech recognition has always helped humans interact with software, but thanks to recent advances in language understanding the cognitive friction of using speech is starting to disappear. This article is about the evolution from traditional voice commands to natural language understanding. The goal, hopefully, is to help determine if natural language can benefit you.
Voice Commands
Unity makes voice commands easy through the use of KeywordRecognizer. Unfortunately, though voice commands are easy and powerful they also represent their own set of challenges for developers.
Let’s take a look at a simple application that lets users interact with an object – a box.

As the developer of this application, we want users to be able to change the color of the box using their voice. So we add the following voice command:

Simple. Let’s support another color.

And another.

Easy! But notice that we had to create 3 separate voice commands? One for each color. And right now our application only understands those 3 colors. If we tell the application to “Make the box yellow” it will either have no effect, or worse – it could change the box to an unexpected color!
Being the prudent developers that we are, we send our app off for user testing. Users tell us that they also want to change the size of the box, so let’s add commands for that too:

At this point, everything is working well. We ship Version 1.0 of the app with 5 voice commands.
A few months pass and version 2.0 adds support for tubes. No problem! We can just copy and tweak the same voice commands we used before.
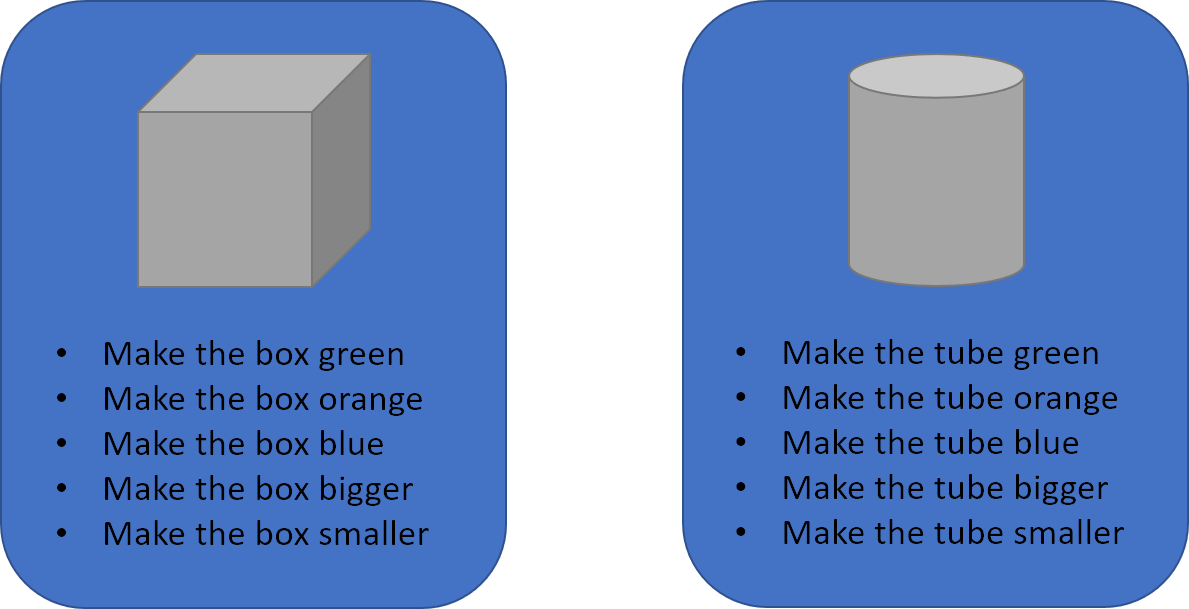
Version 2 goes to user testing and, uh oh, there’s a problem. It turns out that some users have technical backgrounds and they want to refer to objects by their geometric names. We need to add some aliases for our objects.
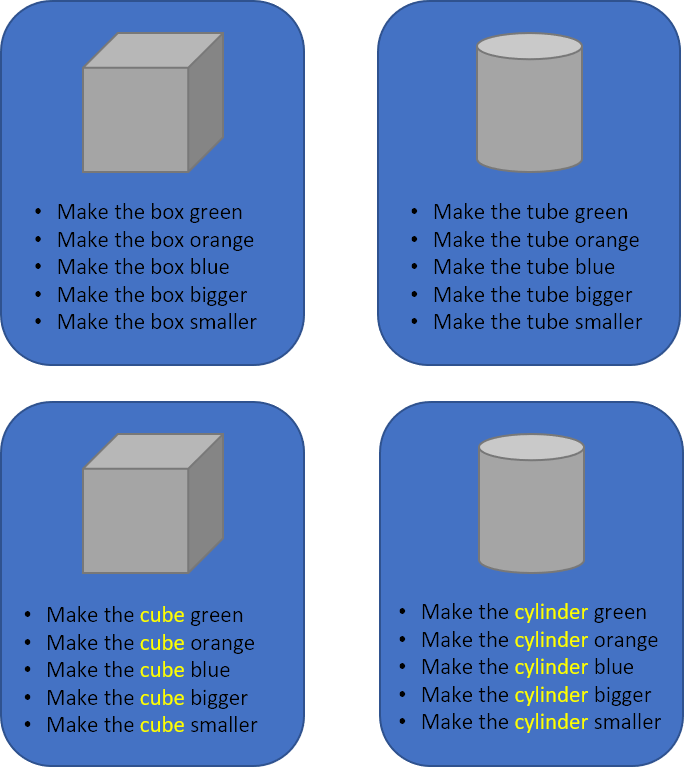
Ouch. The number of voice commands just doubled! We still only support 2 objects with 3 colors and we’re already up to 20 voice commands. And that’s before we add support for the new amazing spheres coming in version 3!
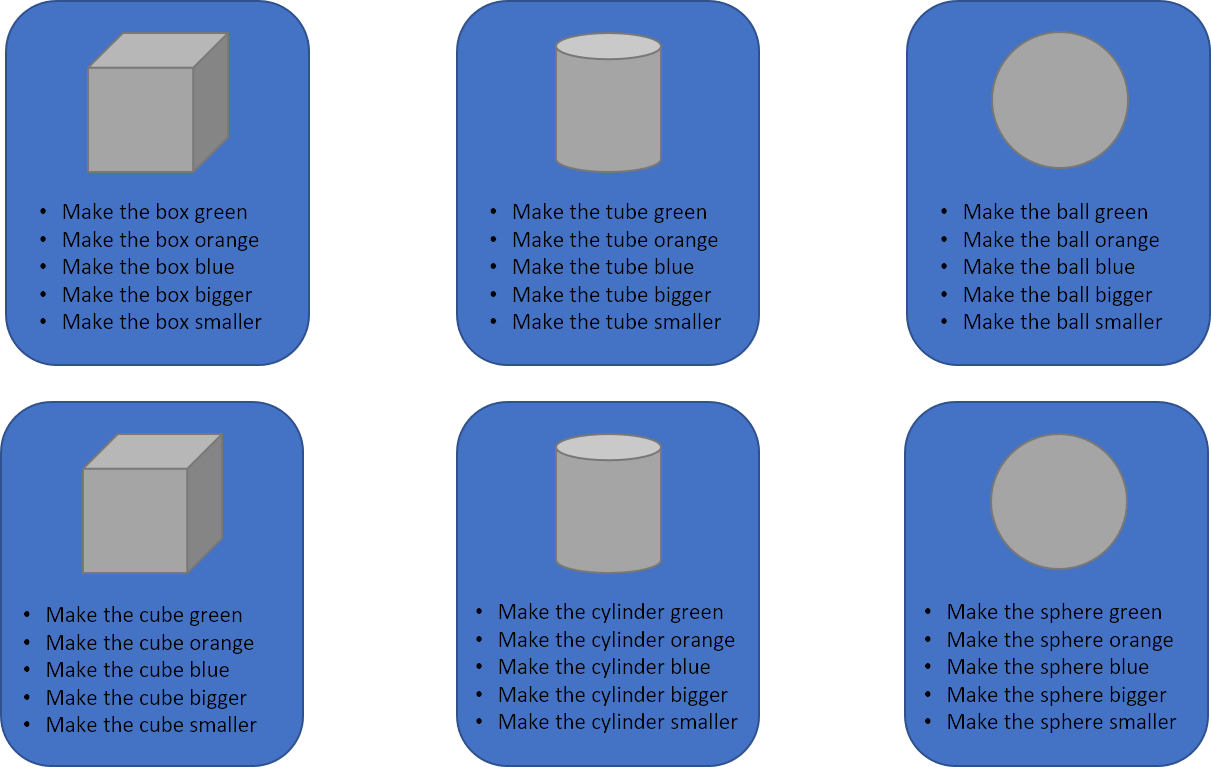
You can see how traditional voice commands could become unmanageable quickly. Even more challenging is the way that humans actually speak. While some users might say “make the cube green”, others might say “turn the cube green”. And in a real-world application there will likely be multiple instances of objects, all with their own unique names and attributes. This is how a simple application with only a few objects can easily grow to over a hundred voice commands.
In summary, comprehensive voice commands (via KeywordRecognizer) can be challenging because they are:
- Atomic – The use of parameters isn’t possible so each combination of object name + color requires its own command.
- Distinct – Referring to the box and the cube requires two commands even though it’s the same object.
- Explicit – Nothing is inferred. If only 3 colors are listed, exactly 3 colors are supported.
Unity includes an excellent class called GrammarRecognizer that addresses many of these problems. Instead of key phrases, GrammarRecognizer uses SRGS grammar files. SRGS has support for rule expansions which allows rules to be combined to make new rules. This helps with the Atomic problem. SRGS also supports alternatives, which allow for aliases and can help with the Distinct problem. But SRGS grammars are still very Explicit – every color and every alias must be defined in the grammar file. SRGS files are also complex to create, and handling a grammar recognition requires understanding semantic meanings. Finally, any update to the grammar file (for example adding an extra alias) requires an update to the application, since grammar files are usually embedded as resources. For many developers, LUIS will represent a more attractive alternative.
Language Understanding with LUIS
Language Understanding avoids the challenges of traditional voice commands because it approaches the problem in a very different way. Instead of trying to recognize what the user has said, language understanding attempts to recognize what the user wants to do.
Imagine visiting a foreign country after studying their language for a year. Armed with basic knowledge of their sentence structure and common nouns, even if you don’t understand all the words in a sentence you can probably figure out what a local is trying to tell you. LUIS works in a similar way.
Intents
In LUIS, intents represent the actions that a user can perform. When we create a new intent, we start by giving LUIS examples of how a user might speak the intent. These examples are called utterances.
For our sample app above, we might create an intent called ChangeAppearance. And that intent might start with the following utterances:

It’s very important to understand that we’re not defining voice commands. Instead, what we’re actually trying to do is teach LUIS a new language! But wait a minute. Based on the examples we’ve given so far, LUIS will learn that when the user wants to ChangeAppearance they will always start their sentence with the words “make the”. In machine learning this is known as overfitting. Of course we know that users will speak this intent many different ways, so we need to teach LUIS a few more examples of how users might say it.

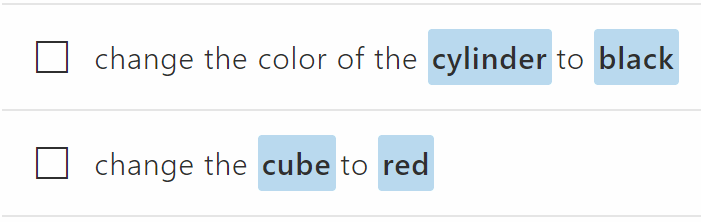
When creating intents, we always want to give LUIS plenty of examples and try to vary the parameters as much as possible. For example, in the screenshots above we see 6 different colors and 4 different shapes.
Entities
So, what are those highlighted words in the screenshots above? I just referred to them as parameters but LUIS calls them entities. Entities can contain a list of known values, but that’s usually pretty rare. Most entities will be of type Simple. You can think of simple entities like placeholders. From the examples above, LUIS will learn that whenever a user says “make the box _____”, the thing that follows box is likely a color. LUIS figures this out by defining an entity called Color and tagging all of the places where Color shows up in a sentence.

Because Color is a simple (placeholder) entity and not a list, we don’t have to teach LUIS about every single color. In fact we can say “make the cube chartreuse” and LUIS will recognize chartreuse as a color – even though we’ve never used chartreuse in a sentence!
Because Color is defined as a simple (placeholder) entity, there is no data validation. The user could just as easily say “make the cube pie” and LUIS will pass “pie” to the application as a Color. With language understanding there is always a trade-off between flexibility and data validation. If an application wants to make sure only real colors are used, it can either change Color to type List and specify the name of every known color or it can use something like ColorUtility.TryParseHtmlString on the client side to try and get a usable color from the string.
What’s Next?
This article barely scratched the surface of natural language, but hopefully it’s given you a taste of what’s possible. In Part 2 – NLU for XR with LUIS we’ll show you how you can use LUIS in your own XR applications.


